









 Videos
Videos
Why Are Vector Databases Becoming Difficult to Scale
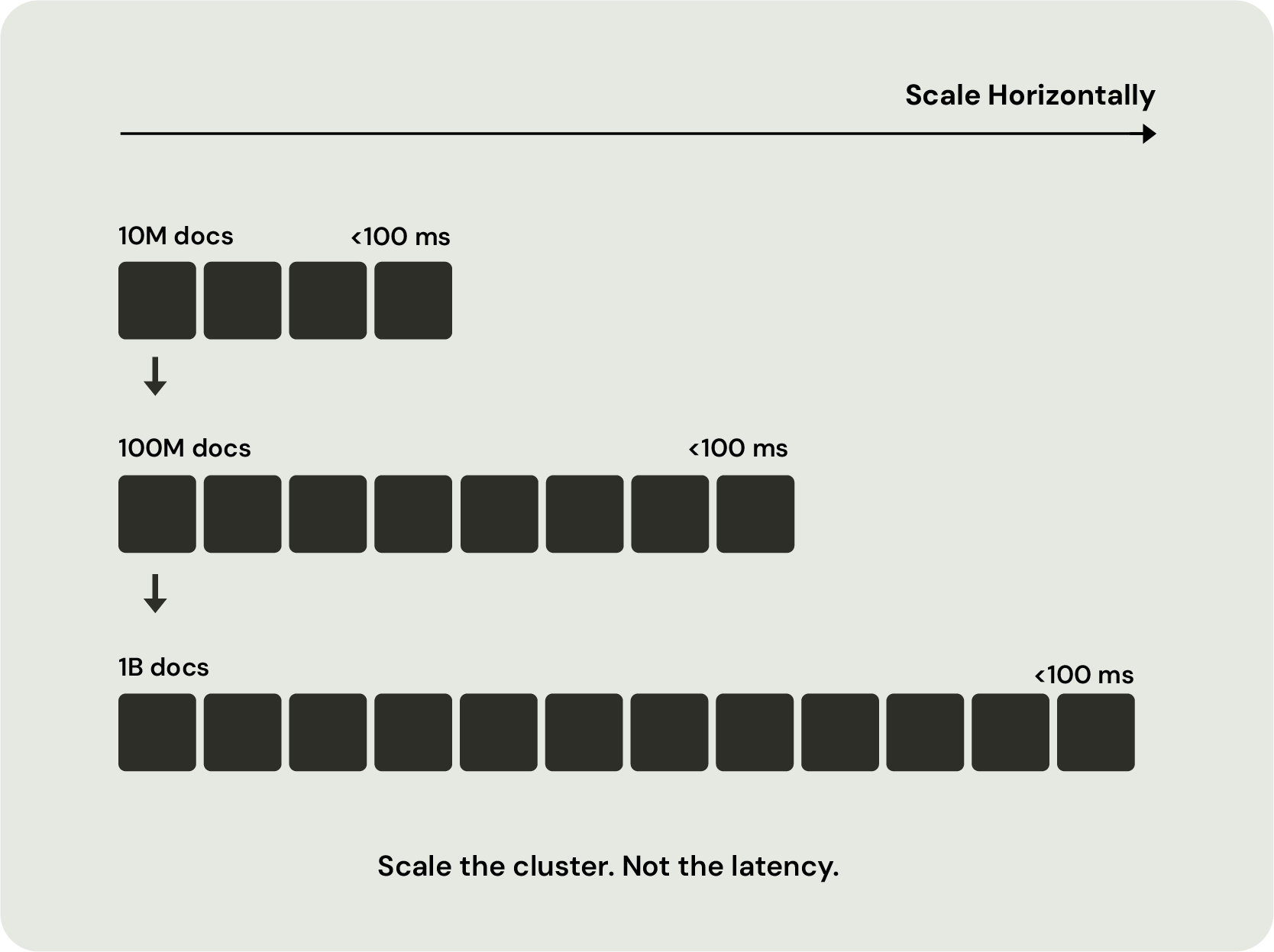
Vector search is only the beginning. Most vector databases perform well when retrieval is the primary requirement. The real challenges emerge as data volumes, query traffic, ranking complexity, and update rates increase.
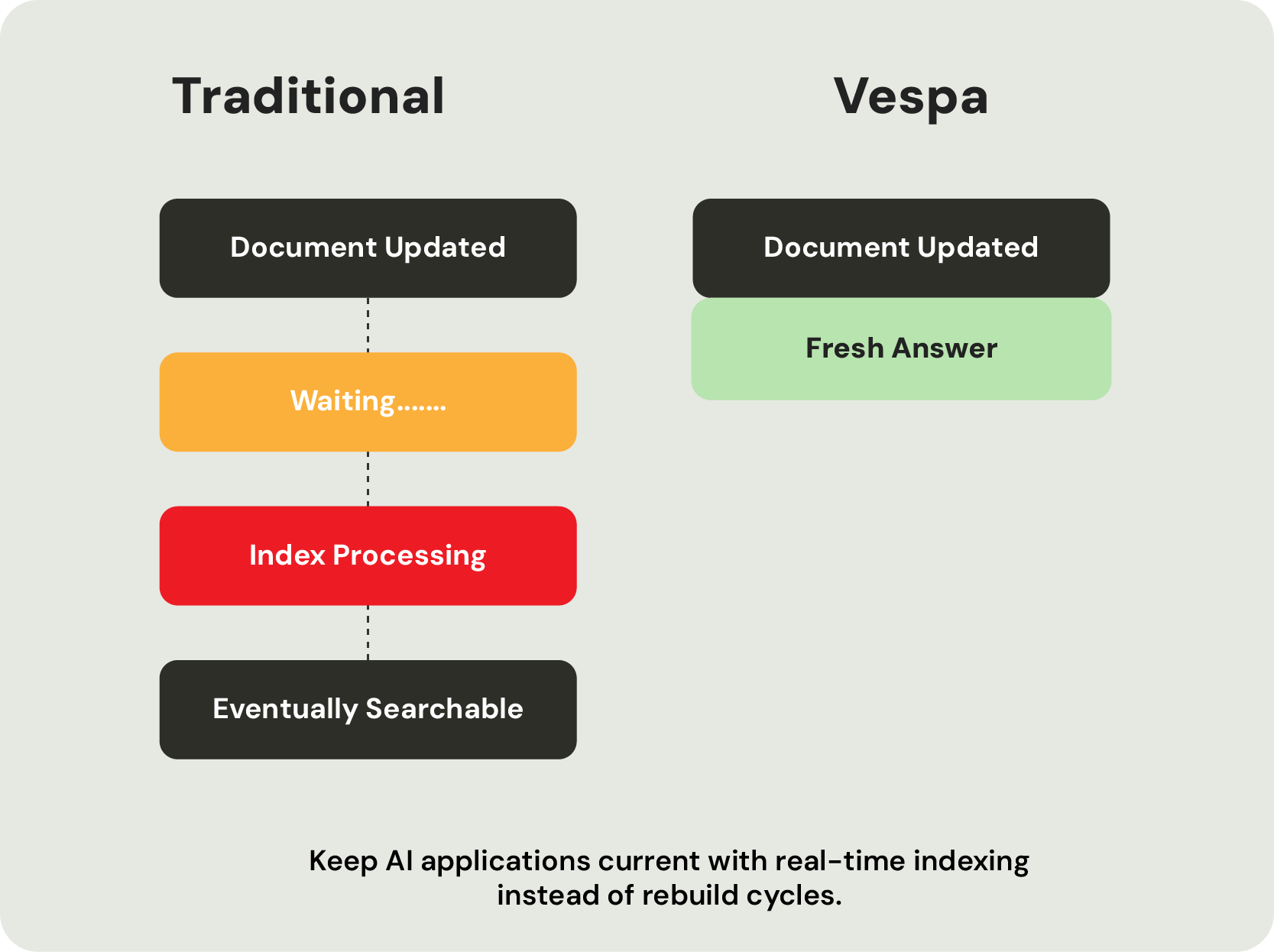
In customer-facing applications, these issues directly impact user experience. Search results become less responsive, recommendations become less timely, and AI applications struggle to keep pace with constantly changing data. The challenge is no longer finding similar vectors. It's maintaining relevance, freshness, and performance as AI retrieval systems become more complex.
Many teams respond by adding more infrastructure: separate systems for vector retrieval, keyword search, filtering, reranking, or even multiple vector databases to balance performance and functionality. Initially, this works well. A vector database handles semantic retrieval, another engine manages keyword search, a reranker improves relevance, and additional services provide filtering or machine learning inference.
Over time, however, every new capability introduces another moving part. Latency increases, operational complexity grows, and tuning becomes harder because retrieval performance now depends on multiple systems working together. The challenge is no longer vector search. It is operating a large-scale AI retrieval architecture.

