AI agents need better retrieval
AI agents depend on retrieval that executes accurately, efficiently, and repeatedly throughout every stage of a task. While they can reformulate queries, explore alternative retrieval paths, and gather additional evidence autonomously, they remain limited by the quality, freshness, and completeness of the information they retrieve.
Unlike human users, AI agents can automatically construct precise queries, combine multiple retrieval techniques, apply structured filters, and refine their approach as they gather new information. Rather than issuing a single search, they may perform dozens or even hundreds of retrieval operations, exploiting sophisticated retrieval capabilities that would be impractical for most human users.
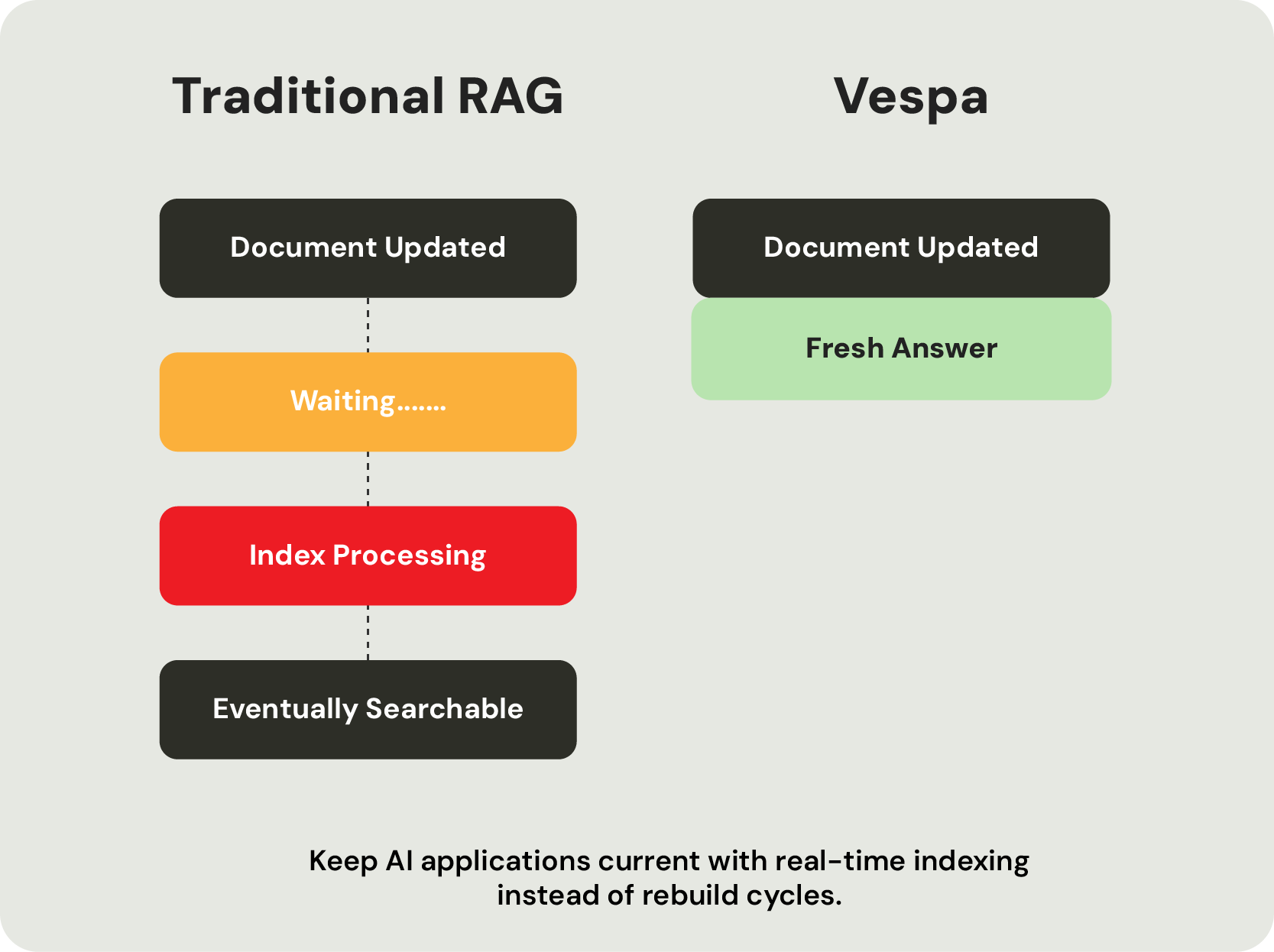
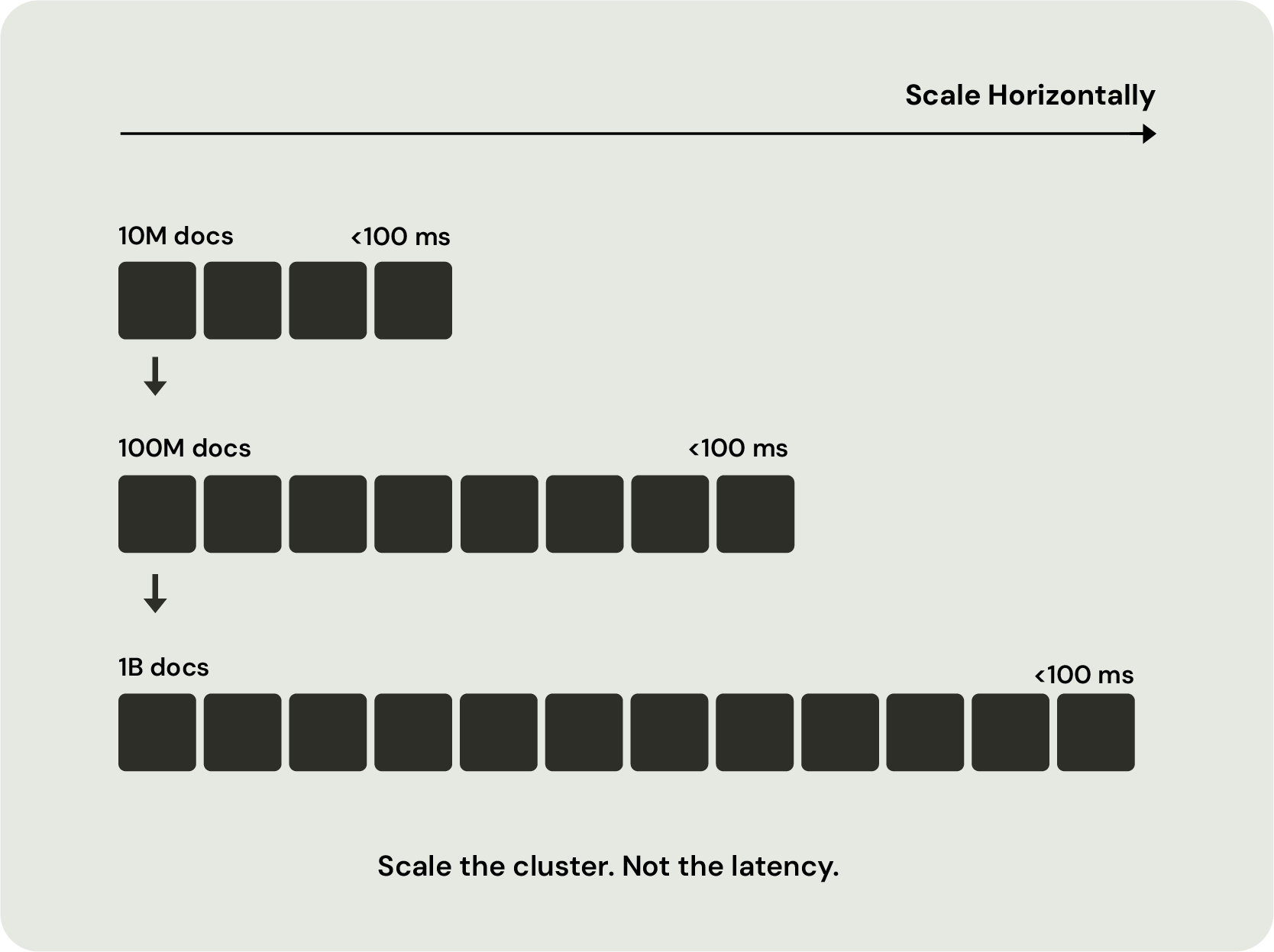
Every retrieval influences the next, making powerful query execution, ranking, and real-time access to fresh data fundamental to the agent's overall accuracy, efficiency, and cost.