Vespa Executes the AI Retrieval Workflow
AI agents depend on retrieval executing accurately, efficiently, and repeatedly throughout every task. Vespa was designed for exactly this challenge. Rather than stitching together separate search engines, vector databases, rerankers, and inference services, Vespa performs retrieval, ranking, filtering, and machine-learning inference within a single distributed serving engine.
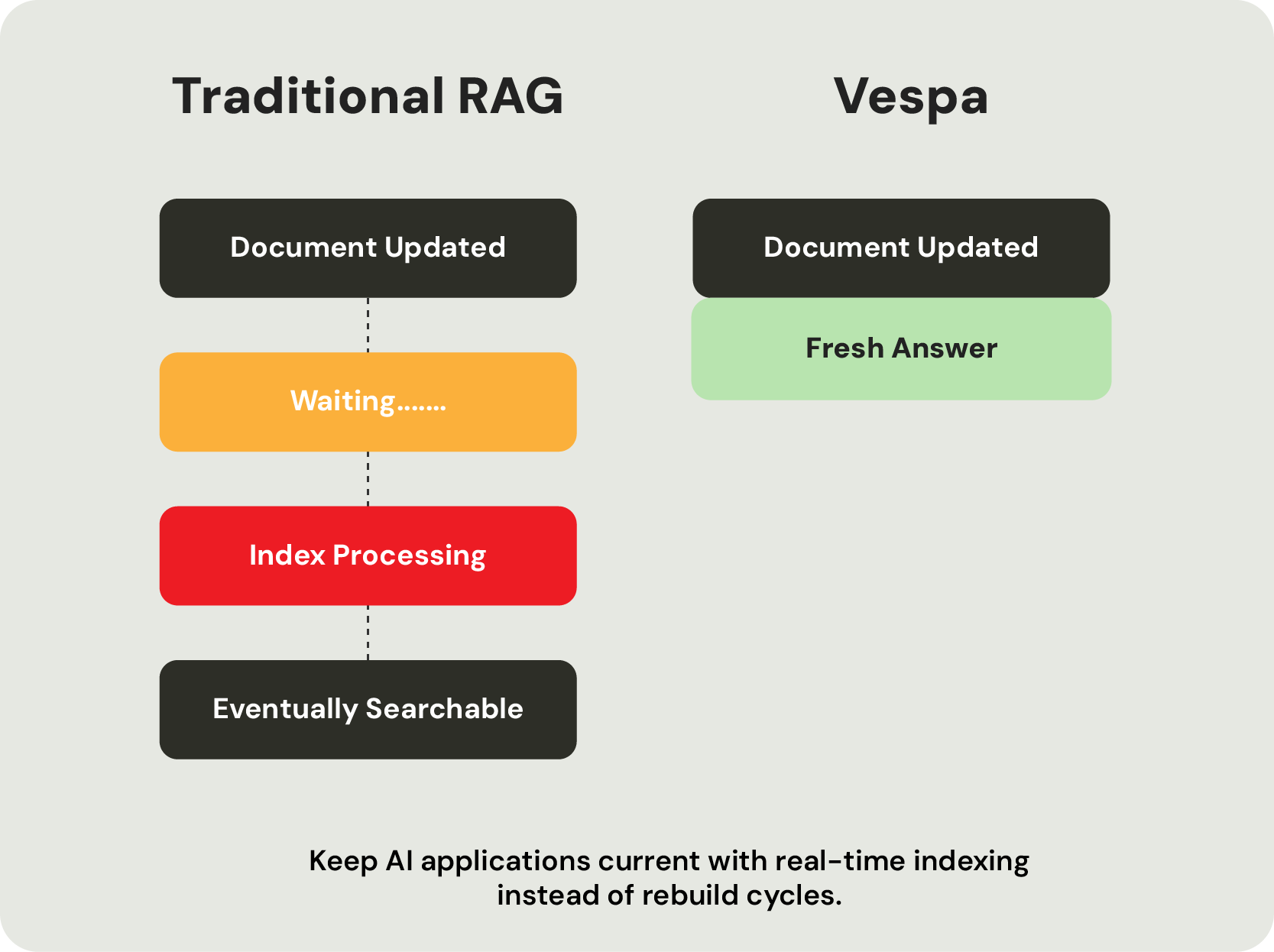
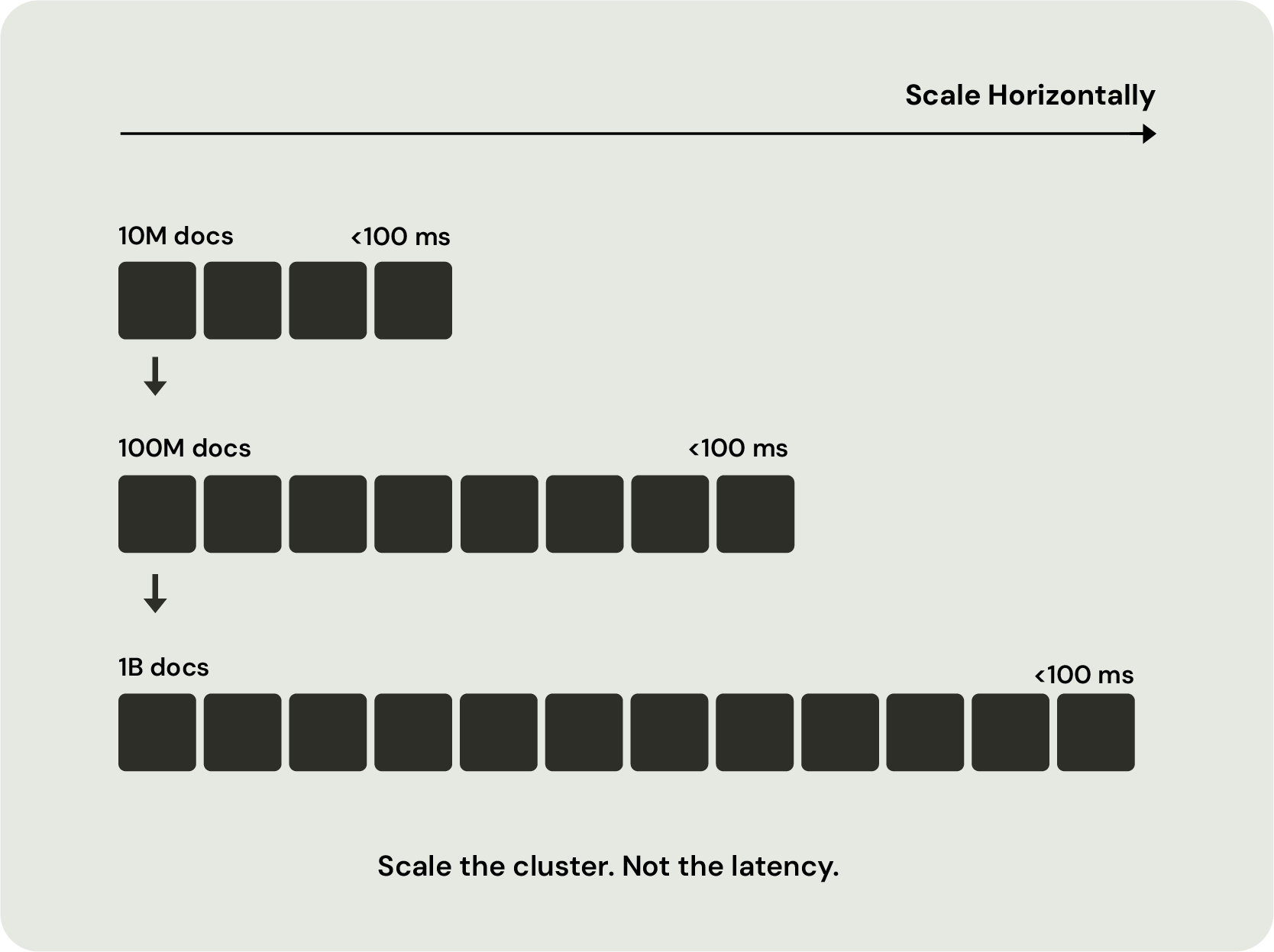
Because retrieval, ranking, and inference execute where the data lives, Vespa minimizes unnecessary data movement while maintaining predictable latency at scale. Continuous indexing keeps information fresh, while unified support for vector, lexical, and structured retrieval ensures every retrieval operation works from the same current state. Multi-phase ranking applies expensive machine learning models only where they improve the final result, maximizing both efficiency and accuracy.
The more autonomous an AI agent becomes, the more important the retrieval workflow becomes. Vespa is designed to execute that workflow efficiently, consistently, and at scale.
This architectural approach doesn't just simplify operations—it also delivers measurable performance benefits. Independent analysis from GigaOm highlights how integrated AI Search Platforms reduce infrastructure complexity, improve performance, and lower operational costs compared with fragmented retrieval architectures.