Role in the AI Retrieval Workflow
Real-time indexing is the stage of the AI Retrieval Workflow that continuously incorporates new and updated documents into the searchable corpus.
Real-time indexing is the stage of the AI Retrieval Workflow that continuously incorporates new and updated documents into the searchable corpus.
Real-time indexing is what separates search that reflects the world right now from search that's always a step behind. Most search and recommendation systems treat freshness as an afterthought: data is batch-indexed on a schedule, and "real-time" means a lag of a few minutes to a few hours. That's a real cost. Stale inventory gets sold, stale prices get shown, stale signals make recommendations worse with every passing minute.
Vespa was built the opposite way. Real-time indexing isn't a mode you turn on; it's the default. Every write, whether a full document or a partial update, follows the same low-latency path: validated, indexed, and made visible to retrieval, ranking, grouping, and sorting, typically in under a second.
No batch windows. No reindex jobs. No stale results.
That architecture is what makes it possible to:
Attribute fields are what enable sub-second indexing and updates. They live in memory and update in place, so changing a price or a counter never means reading the full document from disk, modifying it, and writing it back. The value just changes where it sits.
Index fields, used for full-text matching, follow a similar in-memory-first path: writes land fast, and the heavier work happens in the background, without ever blocking reads or writes.
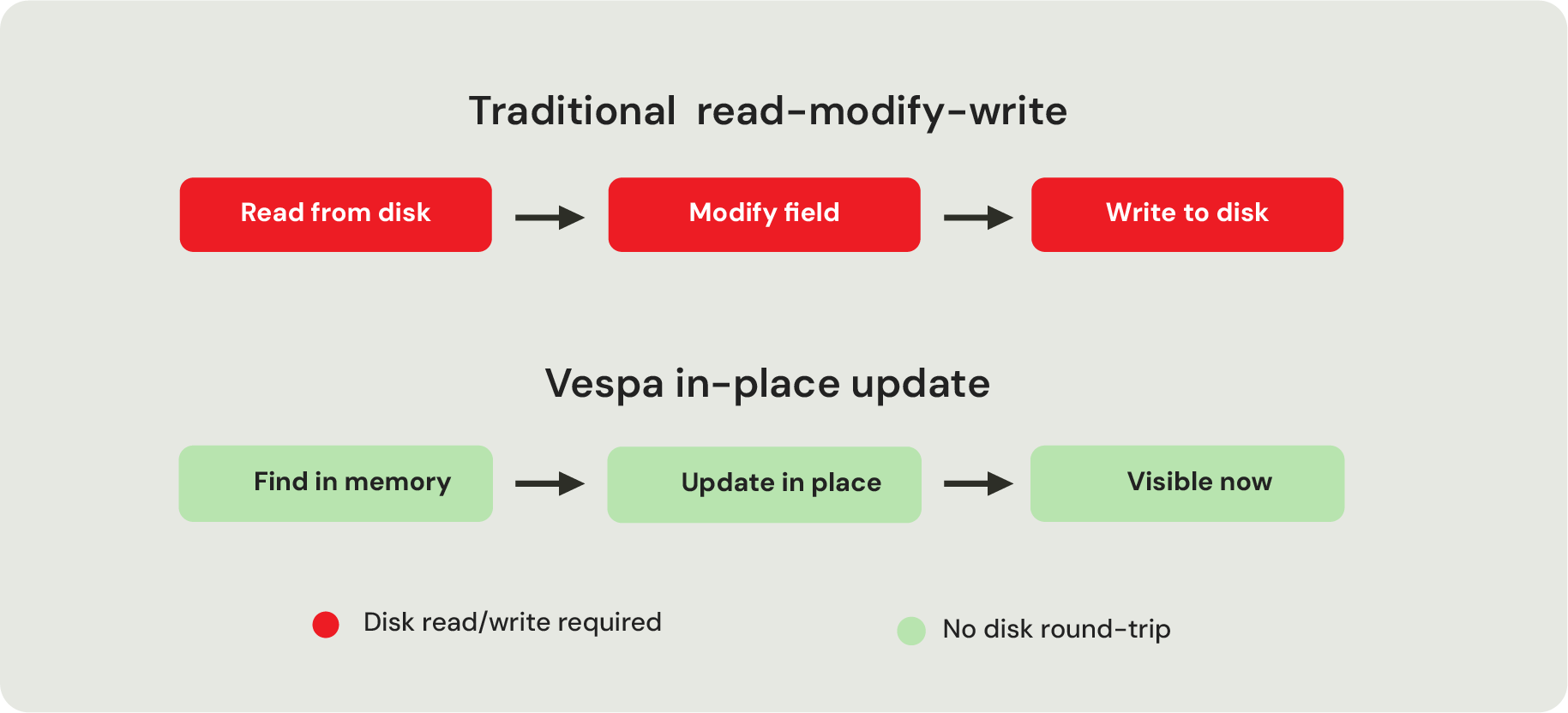
Without real-time indexing, teams either accept staleness (batch windows, scheduled reindexing, eventual-but-slow consistency) or bolt together a separate hot-path system for "live" data and a separate system for everything else, doubling the infrastructure and the ways the two can disagree.
Vespa removes that split: one system, one write path, and the data is live the moment it lands.
Beyond real-time indexing, the write path also provides:
Real-time performance depends on a combination of schema and cluster configuration. The following settings determine how quickly writes become searchable and how efficiently they are processed. Here's what you control:
Frequently Asked Questions