Which AI Platform is Right for You?
Vespa vs the Rest: Built for Real-Time AI at Scale
The AI Search Platform powering companies like Spotify, Perplexity, and Yahoo—Vespa delivers unmatched performance, scale, and flexibility for search-driven applications.
Trusted at Scale
Vespa is built to support real-time, large-scale AI applications, with a core architecture designed around four key pillars: performance, scalability, accuracy, and flexibility. These capabilities are integrated into the system itself—not added as layers—making Vespa well suited for use cases that demand low-latency retrieval, large-scale data processing, dynamic ranking, and adaptable query logic.
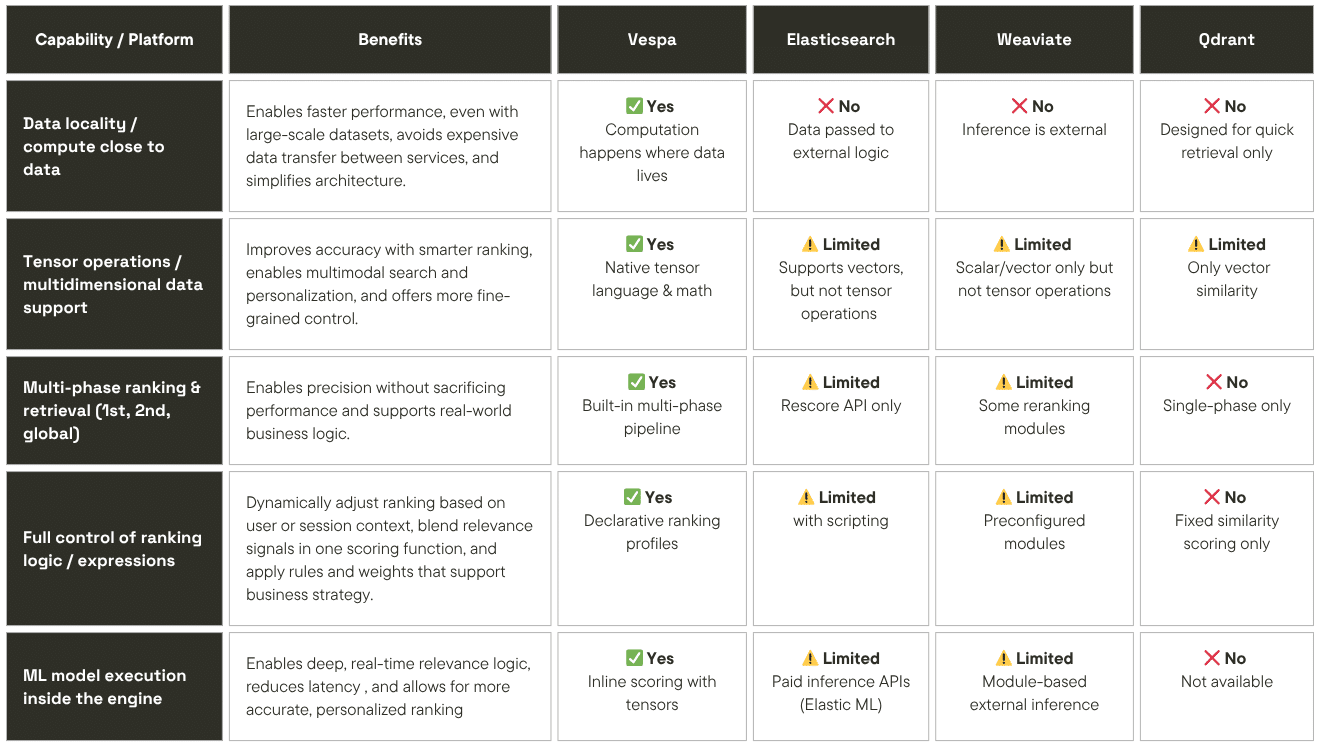
Below is a summary table comparing Vespa to other platforms, followed by more detailed sections on Elasticsearch and Solr.
Vespa Four Value Pillars

Performance
Vespa co-locates data and computation on the same nodes, minimizing network traffic by executing queries and ranking locally. It supports multi-phase ranking—applying lightweight filters first, followed by complex models—ensuring efficient, low-latency execution even at scale.

Scalability
Vespa scales horizontally and vertically without requiring changes to application architecture. It supports gradual growth from prototype to production while maintaining consistent performance and predictable operational load.

Accuracy
Vespa supports structured, keyword, vector, and tensor-based retrieval in a single engine. It applies ranking models (e.g., ONNX, GBDT) and domain-specific logic at query time, enabling precise, low-latency relevance tuning for tasks like LLM grounding, recommendations, and decision support.

Flexibility
Vespa lets teams define custom schemas, ranking logic, and retrieval strategies without modifying core components. It supports external ML models and dynamic query pipelines across structured and unstructured data—adapting easily to complex or evolving requirements.
-
Elasticsearch
Elasticsearch can encounter performance and scalability limitations as data volumes increase. Query speeds often degrade with larger datasets, and scaling typically requires complex shard configurations that add coordination overhead and infrastructure cost. Indexing is resource-intensive, and maintenance tasks—such as updates and schema changes—can temporarily lock out users or disrupt availability. This behavior poses significant challenges in use cases where data is constantly changing and real-time access is critical to business operations.
-
Solr
Solr presents several architectural constraints that limit its suitability for real-time, AI-powered search applications. It lacks native support for combining vector and sparse (e.g., BM25) relevance signals, making hybrid retrieval and advanced ranking approaches difficult to implement without custom extensions. Multi-phase ranking, semantic reranking, and other AI-driven techniques typically require external orchestration and add significant complexity. Solr also lacks built-in support for on-node model inference, which increases latency and introduces additional system components.
Real-time data handling in Solr is hampered by commit-cycle delays, meaning newly ingested data isn’t immediately queryable—an issue for applications requiring instant availability. Scaling is manual, requiring explicit sharding and tuning, which leads to uneven load distribution and operational challenges as data volume and query load increase.

Ready to Unlock the Power of AI?
The AI Search Platform behind Perplexity, Spotify, and Yahoo. Vespa.ai unifies search, personalization, and recommendations with the accuracy and performance needed for generative AI at scale.
Vespa Platform Key Capabilities
-
Vespa provides all the building blocks of an AI application, including vector database, hybrid search, retrieval augmented generation (RAG), natural language processing (NLP), machine learning, and support for large language models (LLM).
-
Build AI applications that meet your requirements precisely. Seamlessly integrate your operational systems and databases using Vespa’s APIs and SDKs, ensuring efficient integration without redundant data duplication.
-
Achieve precise, relevant results using Vespa’s hybrid search capabilities, which combine multiple data types—vectors, text, structured, and unstructured data. Machine learning algorithms rank and score results to ensure they meet user intent and maximize relevance.
-
Enhance content analysis with NLP through advanced text retrieval, vector search with embeddings and integration with custom or pre-trained machine learning models. Vespa enables efficient semantic search, allowing users to match queries to documents based on meaning rather than just keywords.
-
Search and retrieve data using detailed contextual clues that combine images and text. By enhancing the cross-referencing of posts, images, and descriptions, Vespa makes retrieval more intelligent and visually intuitive, transforming search into a seamless, human-like experience.
-
Ensure seamless user experience and reduce management costs with Vespa Cloud. Applications dynamically adjust to fluctuating loads, optimizing performance and cost to eliminate the need for over-provisioning.
-
Deliver instant results through Vespa’s distributed architecture, efficient query processing, and advanced data management. With optimized low-latency query execution, real-time data updates, and sophisticated ranking algorithms, Vespa actions data with AI across the enterprise.
-
Deliver services without interruption with Vespa’s high availability and fault-tolerant architecture, which distributes data, queries, and machine learning models across multiple nodes.
-
Bring computation to the data distributed across multiple nodes. Vespa reduces network bandwidth costs, minimizes latency from data transfers, and ensures your AI applications comply with existing data residency and security policies. All internal communications between nodes are secured with mutual authentication and encryption, and data is further protected through encryption at rest.
-
Avoid catastrophic run-time costs with Vespa’s highly efficient and controlled resource consumption architecture. Pricing is transparent and usage-based.