The Challenge: Delivering Retrieval Accuracy at Scale
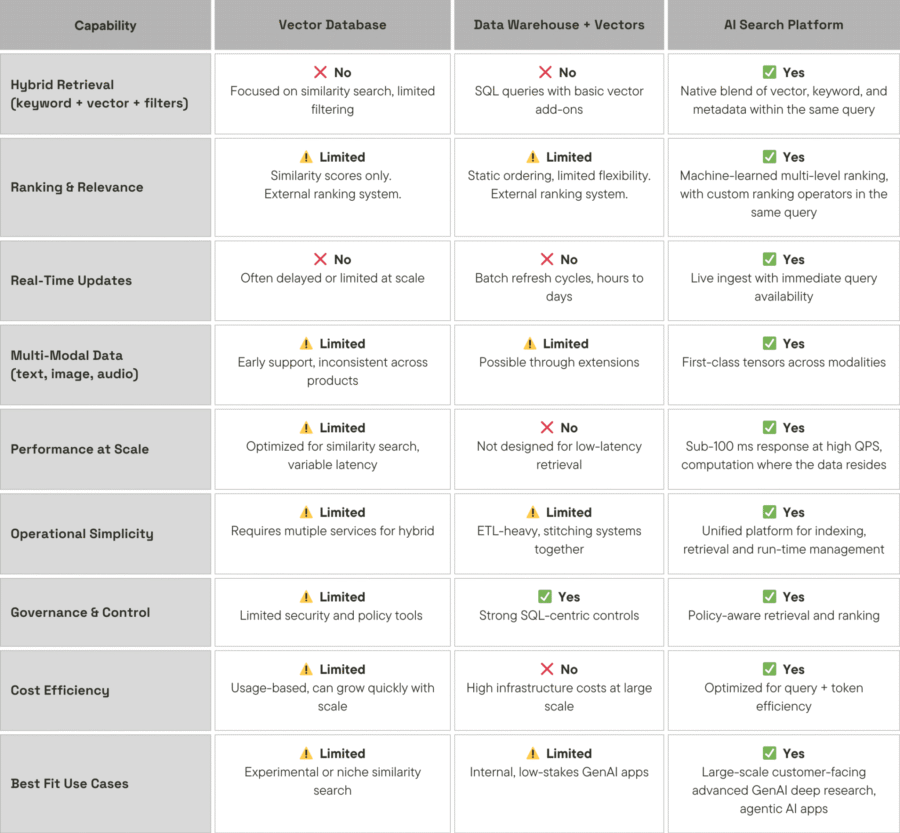
Vector databases enabled similarity search, allowing AI systems to ground responses in large unstructured datasets. However, vector similarity alone is not sufficient for production systems.
Production-grade AI search must combine semantic, keyword, and structured retrieval, apply machine-learned ranking, and manage constantly changing data, all while operating at scale with predictable performance and cost.
When these capabilities are implemented across separate systems, limitations emerge. Bandwidth constraints, integration overhead, and fragmented pipelines introduce latency and reduce accuracy. This becomes a critical issue in applications where users rely on AI-generated results.