

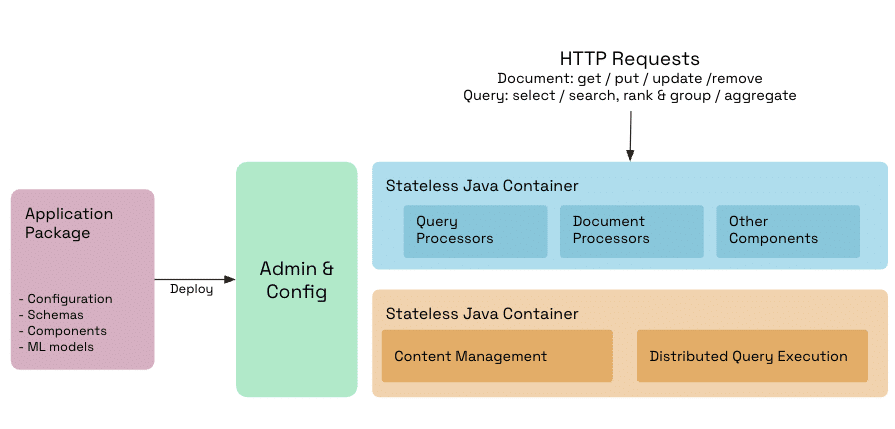
Vespa: Buit for Real-Time AI
Ingest to query in milliseconds: Documents are searchable immediately upon ingestion.
- Partial updates: Modify individual fields without reindexing full documents.
- Extreme throughput: Over 100,000 updates/sec per node for structured fields.
This makes Vespa ideal for systems that benefit from real-time content and signal updates, such as e-commerce sites tracking inventory changes, recommendation systems responding to behavioral signals, and ad systems tracking budget spend.